1. selection sort 선택 정렬
: 가장 작은 것을 선택해 차례대로 맨 앞의 데이터와 바꾸는 정렬 방법
def selection_sort(arr):
n = len(arr)
for i in range(n):
min_idx = i
for j in range(i+1,n):
if arr[min_idx] > arr[j]:
min_idx = j
arr[i], arr[min_idx] = arr[min_idx], arr[i]
#print("sorting ... ",arr)
return arr''' output
sorting ... [0, 5, 9, 7, 3, 1, 6, 2, 4, 8]
sorting ... [0, 1, 9, 7, 3, 5, 6, 2, 4, 8]
sorting ... [0, 1, 2, 7, 3, 5, 6, 9, 4, 8]
sorting ... [0, 1, 2, 3, 7, 5, 6, 9, 4, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 9, 7, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 9, 7, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 9, 7, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 7, 9, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
sorting ... [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
'''
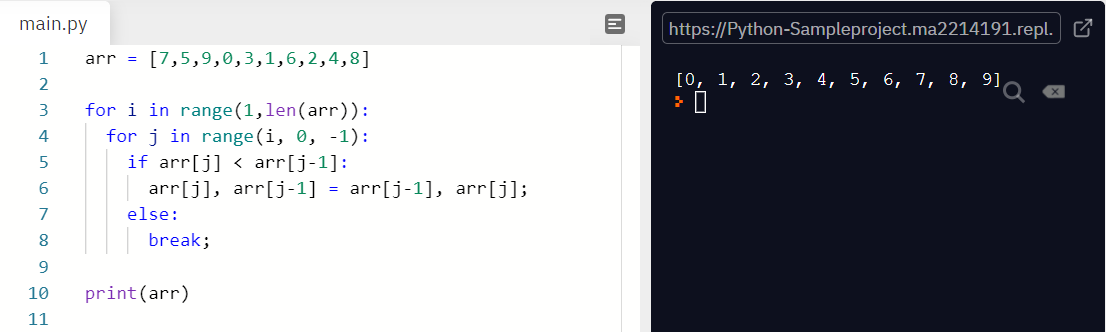
2. Insertion sort 삽입 정렬
: 특정한 값을 적절한 위치에 삽입하는 정렬 방법(그 위치 앞까지는 이미 정렬되어 있음)
def insertion_sort(arr):
n = len(arr)
for i in range(1,n):
for j in range(i-1, -1, -1):
if arr[j] > arr[j+1]: # 해당 데이터의 위치 자동 갱신 가능
arr[j], arr[j+1] = arr[j+1], arr[j]
else:
break
#print("sorting ... ",arr)
return arr ''' output
sorting ... [5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
sorting ... [5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
sorting ... [0, 5, 7, 9, 3, 1, 6, 2, 4, 8]
sorting ... [0, 3, 5, 7, 9, 1, 6, 2, 4, 8]
sorting ... [0, 1, 3, 5, 7, 9, 6, 2, 4, 8]
sorting ... [0, 1, 3, 5, 6, 7, 9, 2, 4, 8]
sorting ... [0, 1, 2, 3, 5, 6, 7, 9, 4, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 7, 9, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
'''나의 실수>
j for문에서 j와 i를 사용하여 값을 비교했는데 이때 i로 인해 업데이트되는 값을 따라가지 못했는데 j+1을 통해 자동으로 값이 업데이트 되는 것을 알 수 있었다.
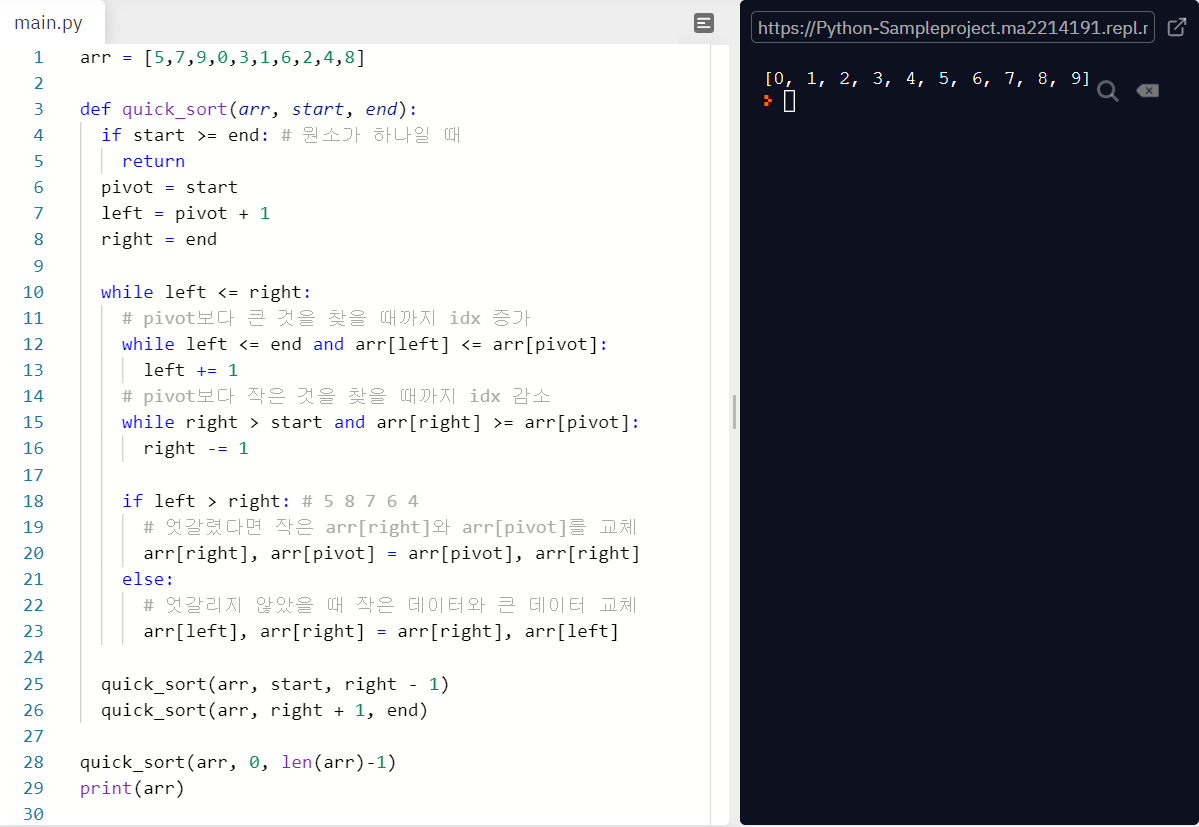
3. quick sort 퀵 정렬
: pivot을 사용하여 왼쪽부터 pivot보다 큰 데이터를 찾고, 오른쪽부터 pivot보다 작은 데이터를 찾아 큰 데이터와 작은 데이터를 찾아 위치를 서로 교환하는 정렬 방법
: 작은 데이터와 큰 데이터를 찾았을 때 index가 엇갈린 경우에는 pivot과 찾은 작은 데이터(right index)와 교체한다
def quick_sort(pivot, end, arr):
if pivot >= end:
return
left, right = pivot + 1, end
while left <= right:
while left <= end and arr[pivot] >= arr[left]:
left += 1
while right > pivot and arr[pivot] <= arr[right]:
right -= 1
if left > right: # 두 값이 엇갈린 경우 작은 데이터(right)와 pivot 교체
arr[pivot], arr[right] = arr[right], arr[pivot]
#print("sorting ... "arr)
else:
arr[left], arr[right] = arr[right], arr[left]
# 현재는 arr[right]에 pivot 값이 존재, pivot은 배열의 앞 부분을 의미
quick_sort(pivot, right - 1, arr)
quick_sort(right + 1, end, arr)
return arr''' pivot이 바뀌는 과정
sorting ... [0, 1, 2, 4, 3, 5, 6, 9, 7, 8]
sorting ... [0, 1, 2, 4, 3, 5, 6, 9, 7, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 9, 7, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 9, 7, 8]
sorting ... [0, 1, 2, 3, 4, 5, 6, 8, 7, 9]
sorting ... [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
sorting ... [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
'''나의 실수> while left <= right:을 생각하지 못했다.
또 배열을 slicing해서 넘기는 바보 같은 생각을 했다... merge할 거 아니면 start와 end idx로 재귀에서 arr을 수정하면 되는데, idx잘 계산해놓고 arr[:right-1], arr[right+1:] 이런 걸 넘기다니 정말 내가 왜 이렇게 짰었는지 도통 모를 일이다.
4. counting sort 계수 정렬
: 별도의 리스트를 선언하고 그 안에 정렬에 대한 정보를 담아 정렬하는 방법
def counting_sort(arr):
count_arr = [0 for _ in range(max(arr)+1)]
for val in arr:
count_arr[val] += 1
arr = []
for i in range(len(count_arr)):
while count_arr[i]:
arr.append(i)
count_arr[i] -= 1
return arr
main 함수
def main():
unsorted = [5,7,9,0,3,1,6,2,4,8]
print("selection_sort",selection_sort(unsorted))
unsorted = [7,5,9,0,3,1,6,2,4,8]
print("insertion_sort", insertion_sort(unsorted))
unsorted = [7,5,9,0,3,1,6,2,4,8]
print("quick_sort", quick_sort(0, len(unsorted)-1, unsorted))
unsorted = [7,5,9,0,3,1,6,2,9,1,4,8,0,5,2]
print("counting_sort", counting_sort(unsorted))
main()''' output
selection_sort [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
insertion_sort [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
quick_sort [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
counting_sort [0, 0, 1, 1, 2, 2, 3, 4, 5, 5, 6, 7, 8, 9, 9]
'''| 선택 정렬 | 삽입 정렬 | 퀵 정렬 | 계수 정렬 | |
| 시간 복잡도 | O(N^2) | O(N^2) | O(logN) | O(N+K) |
'Algorithm&Problem > [Algorithm] 이.코.테.다' 카테고리의 다른 글
| [문제실습] Ch 7. Search (0) | 2021.02.15 |
|---|---|
| [문제실습] Ch 5. BFS/DFS (0) | 2021.02.08 |
| [문제실습] Ch 3. 그리디(greedy) (0) | 2021.01.23 |
| [7일차] 이.코.테.다! Ch6 정렬 (0) | 2020.10.02 |
| [6일차] 이.코.테.다! Ch5 DFS/BFS (0) | 2020.09.22 |